FilesCatcher
FilesCacher
is
a Java program in the first place for scanning html pages (and their
links to other html pages, and so on) for URLs pointed to special
files (e.g. mpeg files), and for automatically download this files.
For a much better program with lots of features (but not in Java) see wget
However, if you are learning Java or are looking for an easy to use
graphical platform independent internet file retrieval utility, this is
definitely for you.
The
development of FilesCatcher started as a programming excercise when I
was learning Java with the free available book "Thinking in Java, 2sd
edition". It was the idea of a couple of people who were reading the
book at that time and were members of "JavaThink", which
is a mailing list for readers of the book.
FilesCatcher is a small Java program that uses many concepts of Java 1.3 together, like IO, Threads, Collections, Network, and GUI classes, showing a practical example of the theory. Its code is easy to understand.
Screenshots:

To download the source click here:
The FilesCatcher project home page is:
http://sourceforge.net/projects/filescatcher/
1) What is FilesCatcher ?
FilesCatcher is a Java program in the first place for scanning html pages (and their links to other html pages, and so on) for URLs pointed to special files (e.g. mpeg files), and for automatically download this URLs.
URLs are internet links to files that can be downloaded. Normally you can click on the name of a file on a web page and the computer ask you if you would like to download this file. That is a URL.
A Java program is a program that can be used in computers under very different operating systems like Microsoft* Windows, Linux, Solaris*, and others.
2) How to run FilesCatcher ?
Before a Java program can be executed in your computer, a Java Virtual Machine (JVM) has to be installed.
You can download the last standard JVM for Windows, Linux and Solaris from www.Java.sun.com
For running Java programs, you only need to download the so called Java Runtime Environment (JRE), and not the whole Java Development Kit (JDK), which is only necessary if you want to write your Java programs.
After installation of the JVM, a doppelclick on the file FilesCatcher.jar should start FilesCatcher. If this does not work, you can start FilesCatcher by typing in the command line: „Java -jar FilesCatcher.jar“
3) Hardware requirements:
FilesCatcher does not need a fast processor to work, but a lot of memory.
If you want to scan less than 100 web pages, FilesCatcher need about 30 MB of RAM, and a computer with 64 MB RAM is enough.
If you want to let FilesCatcher scan 100,000s web pages and download 1000s of files, it need more than 100 MB of RAM and a system with 128 MB of RAM maybe not enough.
3) How does FilesCatcher work?
When you start FilesCatcher, you have to configure it. It means that you have to type at last what kind of files have to be downloaded, what web pages you want to scan, and on which directory FilesCatcher should store the downloaded files. When you do it, you can start FilesCatcher with a click in the Start Button.
FilesCatcher creates automatically three subdirectories with the names „complete“, „incomplete“ and „unknown“. Complete downloaded files are stored in the first subdirectory, incomplete in the second, and files which total size is unknown in the third. The last happens when, for example, the Http Sever does not send the size of the required file.
FilesCatcher renames the files so that you know from which web address the file's URL comes from. The first word of the file's name is the server name (e.g. www.artificialidea.com), then comes the characters „__FilesCatcher__“ and then the name of the file.
An example is: „www.artificialidea.com__FilesCatcher__name.txt“ Here, the name of the file was „name.txt“ and the URL pointed to this file was found in a sub page of „www.artificialidea.com“
FilesCatcher creates in the given directory two data base files (with the name „filesDB.fdb“ and „filesDB.bk“) where it stores the name of the downloaded files. You can delete files from the standard directories of FilesCatcher and it will not try to download the files again, skipping the URLs to this files. If you want that FilesCatcher downloads this files again, you can delete the data base files.
4)What can be configured ?
In the Settings panel, you can configure the follow:
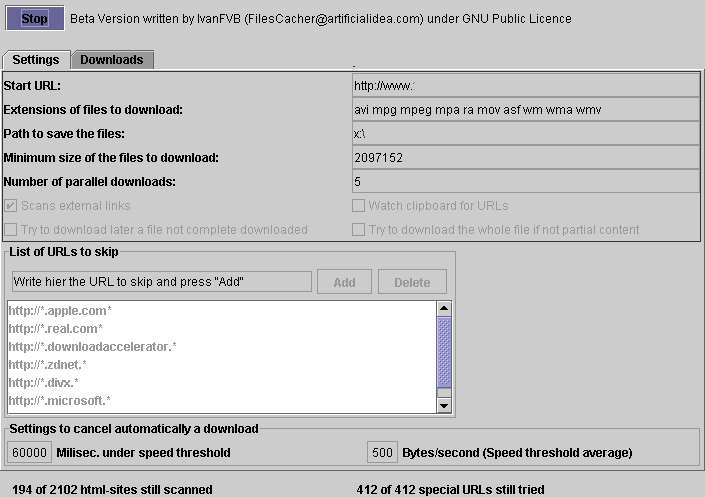
1.„Start URL“ The web site address to be scanned. All links to other web pages will be scanned too if „Scan external links“ is on, and found special files will be downloaded. You can type more than one URL with a space between them. Example of a URL:
„http://www.artificialidea.com/FilesCatcher/index.htm“
2.„Extensions of files to download“ For example, if you want FilesCatcher to download all photos of a web site you can type here „jpg jpeg gif“. Extensions have to have a space between them.
3.„Path to save the files“: A directory on your hard drive. For example „c:\FilesCatcher“. You have to create the directory before.
4.„Minimum size of the files to download“: Files which are less will be not download. This is useful if you, for example, want only to download big movies. The size is given in bytes. So for example 2 MB are 2,097,152 bytes and you type „2097152“ in the field.
5. „Number of parallel downloads“ The maximum number of downloads at the same time.
6.„Scan external links“ If this is on, links to other web sites will be scanned too. If you want to download only the files that are showed in the given URL, set it off.
7.„Watch clipboard for URLs“ If on, you can copy URLs to the clipboard and they will be automatically used by FilesCatcher.
8.„List of URLs to skip“ Here you can add or delete URLs to skip. This means that the URLs will be not downloaded either scanned. For example, „http://*.artificialidea.*“ means that all URLs in which this characters are present like „http://files.artificialidea.com/aaa.gif“ will be skipped.
9.„Settings to cancel automatically a download“ When the speed of a download is less than „Speed threshold“ bytes/sec. during „Millisec. under speed threshold“ milliseconds (1000 milliseconds are one second), the download will be cancel. This is useful to skip very slow downloads.
5) Others
FilesCatcher is Open Source under the
public GNU license. The use of it is at your own risk.